NEWS
RIT presents paper on Automatic Post-Editing at EMNLP 2020
This week, RIT researcher Shamil Chollampatt presented his co-authored paper, “Can Automatic Post-Editing Improve NMT?” at EMNLP 2020, a leading venue for publishing natural language processing research. Being yet another event that was held virtually, EMNLP had put together a number of platforms to replicate the actual conference experience as closely as possible from gather.town virtual spaces that enabled informal meetups and poster sessions, Zoom for talks and Q&A sessions, and Rocket.Chat for paper discussions.
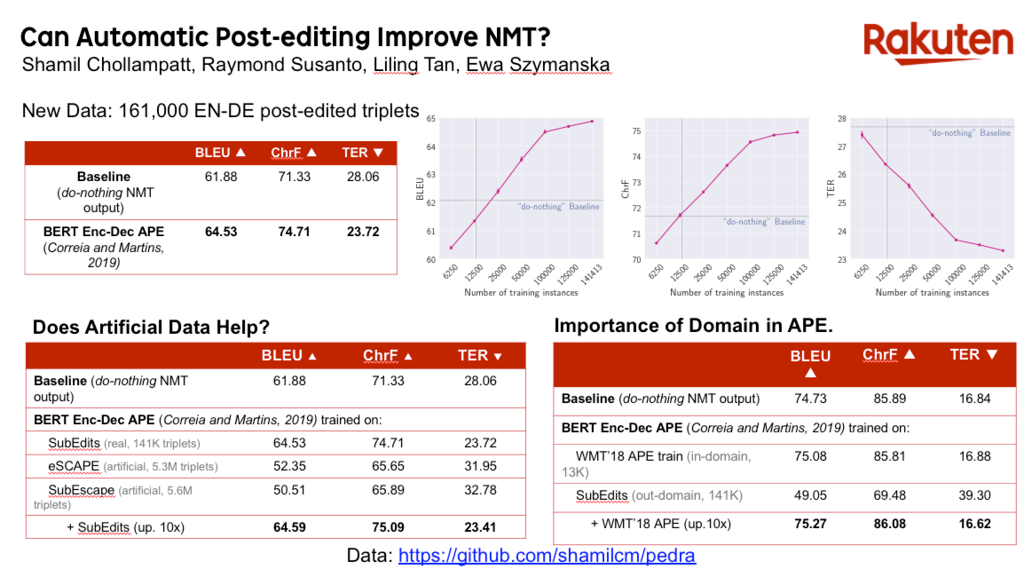
Shamil presented RIT’s paper in the machine translation track of the main conference, which was attended by a wide range of researchers from industry and academia. (The presentation can be found here.) Shamil’s research investigated the usefulness of automatically editing the output of a high-quality neural machine translation using an additional deep neural network. Previous studies have had limited success with this approach, which the paper attributes to the lack of adequate training data. To mitigate the lack of publicly available high-quality data for automatic post-editing, RIT’s publication was accompanied by the free release of a larger scale dataset. The datasets were collected from the subtitle translations and post-edits from Rakuten’s video streaming service Rakuten Viki. The paper was the outcome of RIT’s sustained efforts to push the frontiers of machine translation over the past several years, led by the RIT Singapore team and involving co-authors of the paper, Raymond Susanto, Liling Tan, and Ewa Szymanska.
The Conference of Machine Translation (WMT 2020), which was collocated with EMNLP, also featured exciting work on automatic-post-editing, incorporating terminology constraints based on RIT’s ACL 2020 paper: Lexically Constrained Neural Machine Translation with Levenshtein Transformer. Continuing the trend of recent NLP conferences, a lot of work focused on pre-trained language model representations for multiple NLP tasks. A major push in this direction over the last couple of years has been due to the Transformers Python library (which also won the best demo paper award at EMNLP 2020). Besides, topics like building interpretable NLP models are becoming prominent, as highlighted in one of the keynote sessions. Another topic that is getting much attention in the community has been to build fair, ethical, and unbiased AI, which was the major discussion point of the ethics panel. EMNLP 2020 also had workshops and papers that promoted building environmentally-sustainable and privacy-preserving AI models. Overall, EMNLP 2020 shed light on many under-explored avenues of research in machine translation and NLP.
RIT would like to thank EMNLP and all attendees.