NEWS
Narrowing the theory-practice gap in Reinforcement Learning at this year’s NeurIPS
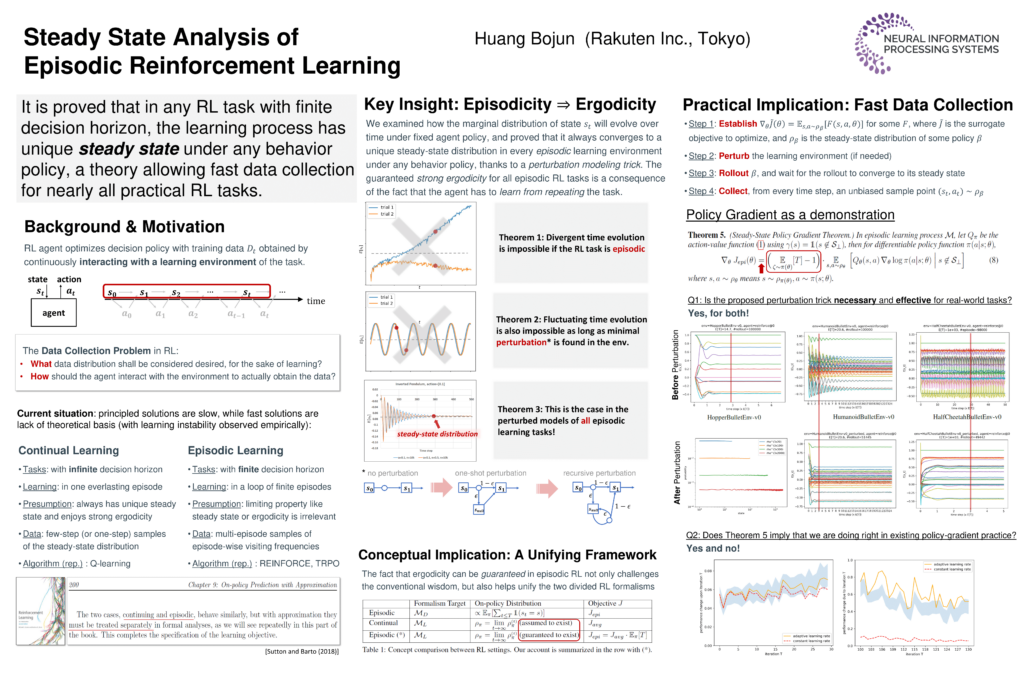
Dr. Bojun Huang of RIT Tokyo presented at the Neural Information Processing Systems (NeurIPS) annual meeting, which was held from December 6-12. NeurIPS is a leading international conference in Artificial Intelligence and fosters the exchange of research on neural information processing systems in their biological, technological, mathematical, and theoretical aspects. The core focus is peer-reviewed novel research, which is presented and discussed in the general session, along with invited talks by leaders in their field. Dr. Huang’s paper was chosen among the record-breaking number of submissions this year, which exceed 10,000.
“Steady State Analysis of Episodic Reinforcement Learning” challenges the conventional wisdom on the subject. In it, Dr. Huang reveals a pervasive structure (called ergodicity) in the currents standard set of Reinforcement Learning (RL) and shows that the identification of this structure enables several new theoretical and experimental observations and insights, which in turn helps mitigate the existing gap between RL theory and practice.
The paper further develops connections between episodic and continual RL for several important concepts that have been separately treated in the two RL formalisms, continual learning and episodic learning. His insights prove that unique steady-state distributions pervasively exist in the learning of environment of episodic learning tasks, and that marginal distribution of indeed approaches to steady-state in essentially all episodic tasks. While steady states are traditionally presumed to exist in continual learning and less relevant in episodic learning, it turns out they are guaranteed to exist for the latter under any behavior policy. Additionally, the existence of unique and approachable steady state implies a general, reliable, and efficient way to collect data in episodic RL algorithms. (This method was applied to policy gradient algorithms, based on a new steady-state policy gradient theorem. He also proposed and experimentally evaluated a perturbation method to enforce faster convergence to steady state in real-world episodic RL tasks.)
RL remains a hot topic at NeurIPS, which accounts for four main-conference tracks out of the seven multi-track conference sessions in total, plus several workshops, expos, and tutorials. Among others, the gap between RL theory and practice is becoming more recognized and there is a general trend that the RL community is trying to mitigate this gap. This includes not only more principled design and analysis of RL algorithms, but perhaps more importantly, increasingly embracing the many insights and lessons learned from real-world RL practices. Dr. Huang and his team are happy to see that their research is helping to bridge the existing gap between theory and practice, contribute to more informed decision-making, and, in due course, bring benefits to the massive commercial application of RL at Rakuten and elsewhere.